
I forrige innlegg fikk du høre hvordan det var å revidere et digert statistikkurs samtidig som det ble undervist, og som fikk første korona-lockdown midtskips samtidig som det blåste opp til storm på alle kanter. Du fikk også vite at da vi så vidt hadde fått kontroll over skuta igjen, kom beskjeden om at vi også måtte finne en løsning for digital hjemmeeksamen for 300 studenter.
«Spoiler alert», skrev jeg, «det ble ikke tid til å blogge».* Men det er ikke det viktigste. Det viktigste er nemlig at vi klarte det! Vi utviklet rett og slett en helt ny måte å lage eksamen på. For:
På kontoret ved siden av meg i Meieribygget sitter min kollega, venn og medpedagog Jon Olav Vik.

Jon Olav og jeg har vokst opp på hver vår side av Fursetfjellet, men vi legger fogderistriden til side når vi klekker ut nye idéer til hvordan vi kan få studentene til å lære enda mer og bedre. Ofte blir vi så revet med av diskusjonene at vi traver rundt på campus (eller til nærmeste åpne is-kiosk) for å avreagere. Ser du oss da, så kom ilende og bli med i diskusjonen! (Vi driver oppsøkende virksomhet også: En intetanende kollega sitter med en kaffekopp på en benk, og før vedkommende rekker å si “økologisk kaffelatte”, har hen fått tutet ørene fulle av ped-prat.)
Jon Olav har ansvaret for innføringskurset STIN100, «Biologisk dataanalyse», et kurs som skal lære studentene grunnleggende programmeringsferdigheter med utgangspunkt i reelle datasett fra biologi. For eksempel får studentene data om bevegelsene til radiomerkede rever, og skal analysere hvor reven rasker.

De beste oppgavene i mitt STAT100 og hans STIN100 er basert på reelle problemstillinger og datasett. Dermed blir det oppgaver om raskende rever, appelsinskrelletid, syrligheten til yoghurt, responstiden til ambulanseutrykninger i midt-Norge, og om kyr bør ha øyne i rumpa for å unngå å bli spist av rovdyr.

Vi som lager oppgavene må både sørge for at studentene lærer det de skal i kursene våre, og samtidig forstå konteksten godt nok til at reveforskerne, meieriprofessoren, ambulansesjåførene og bøndene kjenner igjen sine egne data. De må også synes at spørsmålene som stilles er gode, sett fra økologiske, meierifaglige, medisinske eller landbruksfaglige ståsted. De beste spørsmålene kombinerer alt dette med spesifikke læringsmål i kursene våre, og vekker samtidig interesse hos studentene.
En av de pedagogiske utfordringene vi stadig kommer tilbake til, er hvordan vi skal få gitt studentene nok mengdetrening. Vi kjenner alle til de repetitive oppgavene fra den gangen vi lærte oss gangetabellen. Eller pugget tyske gloser. Noen øver tusen ganger på å sparke en ball i mål, noen spiller skalaer og intonasjonsøvelser på oppstrøk og nedstrøk, og noen har sittet inne i finværet for å kommet seg videre til neste nivå i yndlingsdataspillet sitt.

Dette trengs for å automatisere ferdigheter, så vi kan mestre de komplekse oppgavene: Spille fotball i eliteserien, Verdis Requiem i orkesteret, på det øverste nivået i dataspillet, eller få til de sammensatte oppgavene i STAT100 og STIN100.
Ett datasett gir én mulighet til å øve på hvert spørsmål som formuleres. Men mange studenter synes det er vanskelig å få det til på første forsøk. Hadde vi hatt to datasett, ville vi fått variasjon i tallene, og da kunne vi tilbudt en ekstra treningsoppgave. Eller enda bedre: Hvis vi kunne simulere data fra et gitt utgangspunkt, kunne vi lagd mange ulike oppgaver basert på samme spørsmålsstilling!

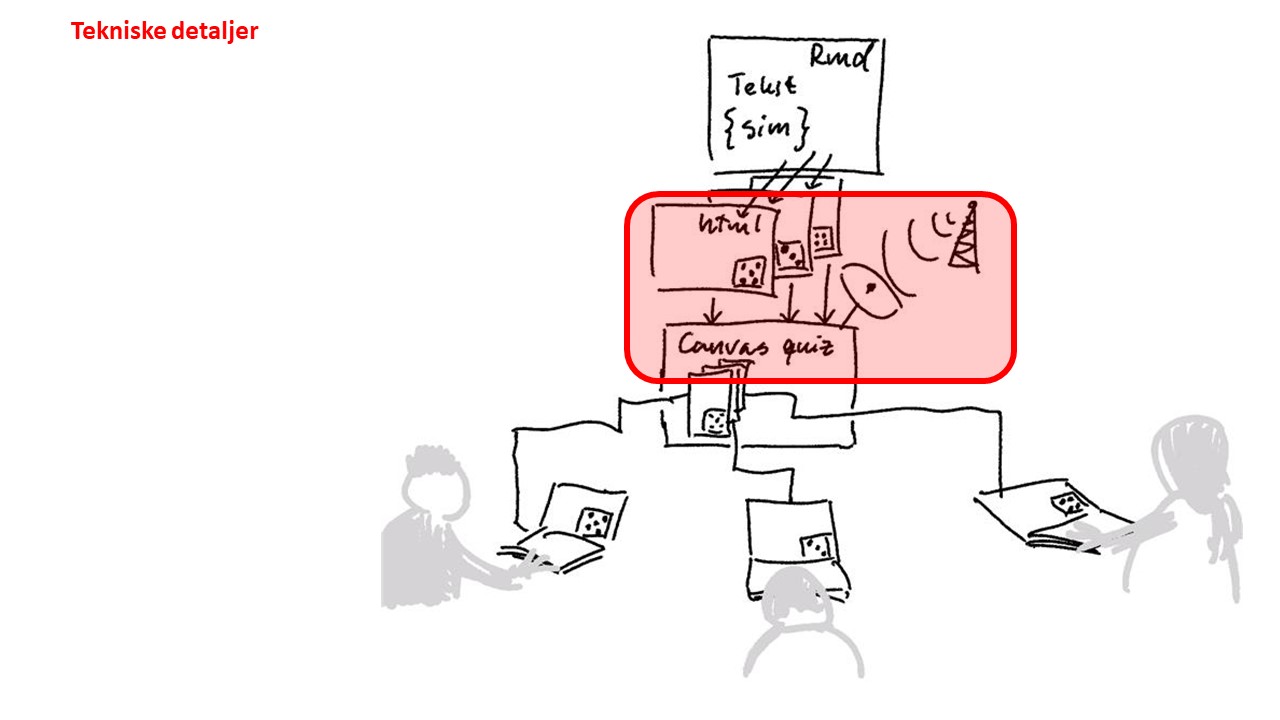
Da første korona-lockdown kom, hadde Jon Olav allerede begynt å utforske dette. Mer spesifikt: mens jeg brukte arbeidstida på å finpolere ppt-ene til undervisningsfilmer, og løpe til og fra opptaksstudio, hadde kontornaboen tentaklene laaangt inne i det indre av lærings- og eksamenssystemene våre (Canvas og WISEflow), og undersøkte om og i så fall hvordan mengdetreningsoppgaver kunne lages med dataverktøyene RStudio og R markdown og programmatisk legges inn i systemene.
Synes du dette ble litt vel teknisk? Det er det også. Men poenget er at hvis det er mulig, åpner det seg et hav av muligheter. Inkludert muligheten til å lage individualiserte eksamensoppgaver.
Digital hjemmeeksamen: Potensielt blodig urettferdig!
På en digital hjemmeeksamen er det vanskelig, om ikke umulig, å kontrollere eller forhindre at studenter sitter sammen med smarte venner og hjelper hverandre. Å hjelpe hverandre er strålende underveis i semesteret, men eksamenskarakteren skal vise hva akkurat du kan, og samarbeid er juks. Allikevel har vi hørt og lest at det skjer, til dels i stor skala. Men det blir ikke mindre blodig urettferdig av at mange gjør det.
Vår løsning på urettferdigheten og jukseproblematikken er enkel: Alle studentene får de samme statistiske spørsmålene og utfordringene, men enkelte aspekter av spørsmålene, utregninger, vurderinger og svaralternativer er basert på data og tall som er unike for det ene oppgavesettet de selv skal løse. Siden det er mange oppgaver og mye å jobbe seg gjennom, hjelper det lite å sitte sammen med smarte venner, for det er tidkrevende å samarbeide når ting ikke er helt likt. I en tre-og-en-halv-times eksamen med 40 spørsmål er det ikke tid til det. (Det var «helt ærlig et sirkus på lesesalen», sier en av studentene om å samarbeide om slike oppgaver.) Dermed må studentene løse sine egne oppgaver, og en rettferdig(ere)* digital hjemmeeksamen er en realitet!

Prinsippet er rørende enkelt. Implementeringen av prinsippet – vel… Det kostet noen drøye arbeidsuker å komme frem til bildet du ser like over, for å si det sånn. Den 17/3-2020 opprettet Jon Olav et nytt repositorium på gitlab (du trenger ikke å vite hva det er), og så kastet vi oss ut i et digitalt maratonløp uten sidestykke.
Kort oppsummert: På de 8 ukene frem til eksamen 14. mai, programmerte Jon Olav alt som trengtes for å få maskineriet til å virke (det var ikke lite!), og testet det ut på en parallell kursside. Selv satt jeg i stua hjemme mellom flygelet ogTV-en (begge deler ble brukt) fra tidlig morgen til langt på natt, og konstruerte og programmerte 40 ulike flervalgsoppgaver som dekket alle de viktigste delene av pensum. I hver oppgave ble data simulert på nytt for hver student, og de 6 svaralternativene til hver oppgave ble spesialtilpasset de opplysningene som ble oppgitt i oppgaven.
Jeg har en del erfaring med R, og skrev hovedoppgaven min i LaTex for 25 år siden, men var nybegynner i Markdown, og totalt blank i git, som vi brukte til revisjonskontroll. Læringskurven var like stupbratt som kveldene var lange, helgefri var det bare å glemme, og eksamensdagen nærmet seg nådeløst. Det var et mentalt blodslit. Og det var veldig, veldig tilfredsstillende å få det til. (Og nei: Det ble ikke tid til å blogge.)

Heldigvis fikk vi på kort varsel en fantastisk sensor på laget: Mette Langaas fra NTNU. Hun var blidt, oppmuntrende og faglig sterkt til stede for oss under innspurten. Mette korrekturleste både det statistikkfaglige og programmeringen min med statistisk falkeblikk og lynrask presisjon, og takket være henne fikk vi luket ut mye rusk som vi i all jobbingen ikke hadde overskudd til å fange opp.

Til slutt gjensto å bruke en natt på å oversette til nynorsk (oversettelsestjenesten apertium anbefales på det varmeste!), før alle de 344 individuelle bokmålske oppgavesettene og deres 344 nynorske motstykker ble lastet opp til læringsplattformen Canvas. Innlastingen var ferdig akkurat i tide til at vi kunne bruke morgenen 14/5 på å sove litt i sola mens vi ventet på at klokka skulle bli 14.00, og eksamen skulle starte.

Helt feilfri ble den ikke, eksamenen som gikk på lufta 14. mai 2020, men studentene ble godt kompensert for mine feilprogrammeringer, og vi gjorde oss verdifulle erfaringer til de neste digitale hjemmeeksamenene. For én gang må alltid være den første.
Og for et pedagogisk løft den var, denne eksamenen!
I ettertid har vi gjennomført samme eksamensform både H2020 og V2021. Stadig flere kontrollrutiner er programmert inn for å sikre at alle de simulerte tallene gir fornuftige scenarier for alle studentene. Og gjennomføringsrutinene er så gjennomarbeidet at stressnivået er akseptabelt også for oss to som er ansvarlige for at det hele fungerer.

Dessuten benytter vi nå det samme prinsippet til å gi studentene nettopp den mengdetreningen underveis i kurset, som var motivasjonen vår for i det hele tatt å begynne med dette.
Eksempelvis får studentene ofte ett sett med oppgaver som har superdetaljerte løsningsforslag. Så får de noen flere oppgaver som ligner, men som har andre tall, og som de kan øve mer på. I slutten av uka får de så en ukesluttest med enda en ny versjon av de opprinnelige oppgavene. Slik kan vi tilby studentene god trening og detaljert hjelp underveis.
I digital undervisning er dette svært nyttige og gode hjelpemidler, fordi tilgang til detaljerte løsningsforslag og samtidig muligheten til å øve mer på det samme, gjør flere studenter selvhjulpne. Dermed kan lærer-ressursene brukes på de som trenger mer eller annen hjelp.
Er du interessert i å vite mer om selve eksamensprosjektet, kan du lese om det i denne Khrono-artikkelen, eller se presentasjonen vår på webinar om digitale vurderingsformer:
«Men åkei,» tenker du kanskje nå, «dette er vel og bra og interessant og alt det der, men hva med lydmuren, da? Alt det som beskrives i dette blogginnlegget foregikk jo våren 2020, men Statistrikk gikk ikke viralt og gjennom lydmuren før høsten 2020. Så hva skjedde, egentlig, på strikkefronten og sånn?»
Det er i så fall et betimelig spørsmål. Og det tar oss over til lydmurhistoriens tredje del: Sommerferie og CoviDesign. Følg med i neste episode!
* «Ikke tid til å blogge» er ikke helt sant, for jeg strikket så infernalsk mye foran TV-en i denne tiden, at jeg faktisk klarte å begå innlegget om #altblirbrasitteunderlagene. Men ser du litt nøyere på det, er det et innlegg fullt av strikking og pene bilder av blomster, men med fint lite statistikk. Og da er det strengt tatt ikke statistrikk, er det vel?
** «Juksesikker hjemmeeksamen» ble valgt som slagord fremfor «rettferdig hjemmeeksamen» bare fordi vi likte allitterasjonen.

Ufda, som en inkarneret humanisk fatter jeg ikke meget af det, du her fortæller, bortset fra at det endte med nopgle meget, meget smarte «juksesikre hjemmeeksamen». Det siger meget om din medrivende skrivestil, at jeg faktisk læste det hele!
Jeg strikker stadig appesiner (og vandmeloner) efter din opskrift(med modifikationer – ellers ville jeg ikke være mig) ind i mellem, og er meget taknemmelig for at du kaster dig gennem lydmuren.
Det tar jeg som et stort kompliment, Charlotte, tusen takk!
Og så godt å høre at du modifiserer. Det er fint å vite at idéen videreutvikles og at andre finner sin egen vri. Jeg har selv store problemer med å følge en oppskrift uten å endre noe… Men nå ble jeg plutselig veldig inspirert til å strikke meg en vannmelon!
Det var skam også ment som en kompliment 🙂
Tak for forståelsen.
Det kunne være interesant at se, hvordan du ville strikke en vandmelon … så lad være at kigge på min blog og lav din egen og så post den her?
Hihi, challenge accepted! (Men det kan fort ta noen uker eller måneder – det blir en travel høst!)